Getting started with move2utils
Source:vignettes/OUTLIER_1_getting_started.Rmd
OUTLIER_1_getting_started.Rmdmove2utils cleans GPS and satellite tracks by composing
four outlier-detection primitives — bridge residual (geometric),
path-vs-displacement detour ratio (geometric, time-insensitive),
movement-metric probability (kinematic), and step-level speed cap
(physical) — under a single iterative entry-point,
mt_clean_track(). This vignette walks through that one-call
workflow on a bundled synthetic track with known outliers, then briefly
tours each primitive for readers who want finer control.
Load data
This vignette uses the CPF_A track from the package’s
bundled synthetic data — a 1748-fix central-place-forager simulation
with 23 graded outliers injected at known positions. The same track is
the demonstration fixture in vignettes 3, 4 and 5, so cascade behaviour
can be compared across them. For narrated cleaning on real GPS tracks
see the OUTLIER_example_* vignettes listed in “Further
reading”.
library(move2)
library(sf)
library(move2utils)
## CPF_A synthetic track (1748 fixes, 23 known outliers)
path <- system.file("extdata/synthetic_tracks.csv.gz",
package = "move2utils")
tracks <- mt_read(path)
cpf_a <- filter_track_data(tracks, .track_id = "CPF_A")
cat(nrow(cpf_a), "locations for CPF_A\n")
#> 1748 locations for CPF_AIf you’re pulling your data from Movebank, jump to the appendix at the end of this vignette for the recommended download pattern — it matters which attribute columns you ask for, because the cleaning pipeline can use Movebank’s per-fix quality information to sharpen its decisions.
The one-call workflow
mt_clean_track() runs the four primitives in turn,
applies the class-aware consensus rule by default, expands topologically
isolated blocks, and iterates until no new fixes are flagged. By default
it returns the cleaned track ready for downstream analysis. The default
consensus can be changed via consensus = — see
?mt_flag_consensus for the available modes
(class_aware, strict, majority,
speed_trusted, any, or
custom).
clean <- mt_clean_track(cpf_a)
#> No physiological speed cap supplied -- running with a data-driven cap chosen from your track. This works well for most cases. If your animal has multiple behavioural states (e.g. perched and flying) or you expect sustained-spoof errors, supplying `v_max =` (a published top speed in m/s) or `(mass = ..., mode = ...)` for the allometric estimate gives sharper results. See `?v_phys_estimate` for the allometric helper; `?mt_clean_track` documents the failure modes of the auto-cap in detail.
#> Auto-cap landed at 60.2 m/s -- above the Hirt 2017 95% upper CI of the maximum biological speed (~52.6 m/s). The gap finder is detecting a structural break within the outlier tail. Supply `(mass, mode)` or a hard `v_max` for a principled physiological cap. See `?v_phys_estimate`.
#> Iter 1: bridge=20 prob=5 speed=23 detour=11 (v_max=60.2) | conjunction=19 | new=19 cumulative=19
#> Iter 2: bridge=4 prob=17 speed=6 detour=5 (v_max=25.5) | conjunction=6 | new=6 cumulative=25
#> Iter 3: bridge=0 prob=12 speed=0 detour=2 (v_max=-) | conjunction=0 | new=0 cumulative=25
#> === mt_clean_track: 25 flagged (1.430% of 1748); stopped: no_new_flags ===
#> Returning the cleaned track (1723 rows). To inspect what was flagged, re-run with remove = FALSE.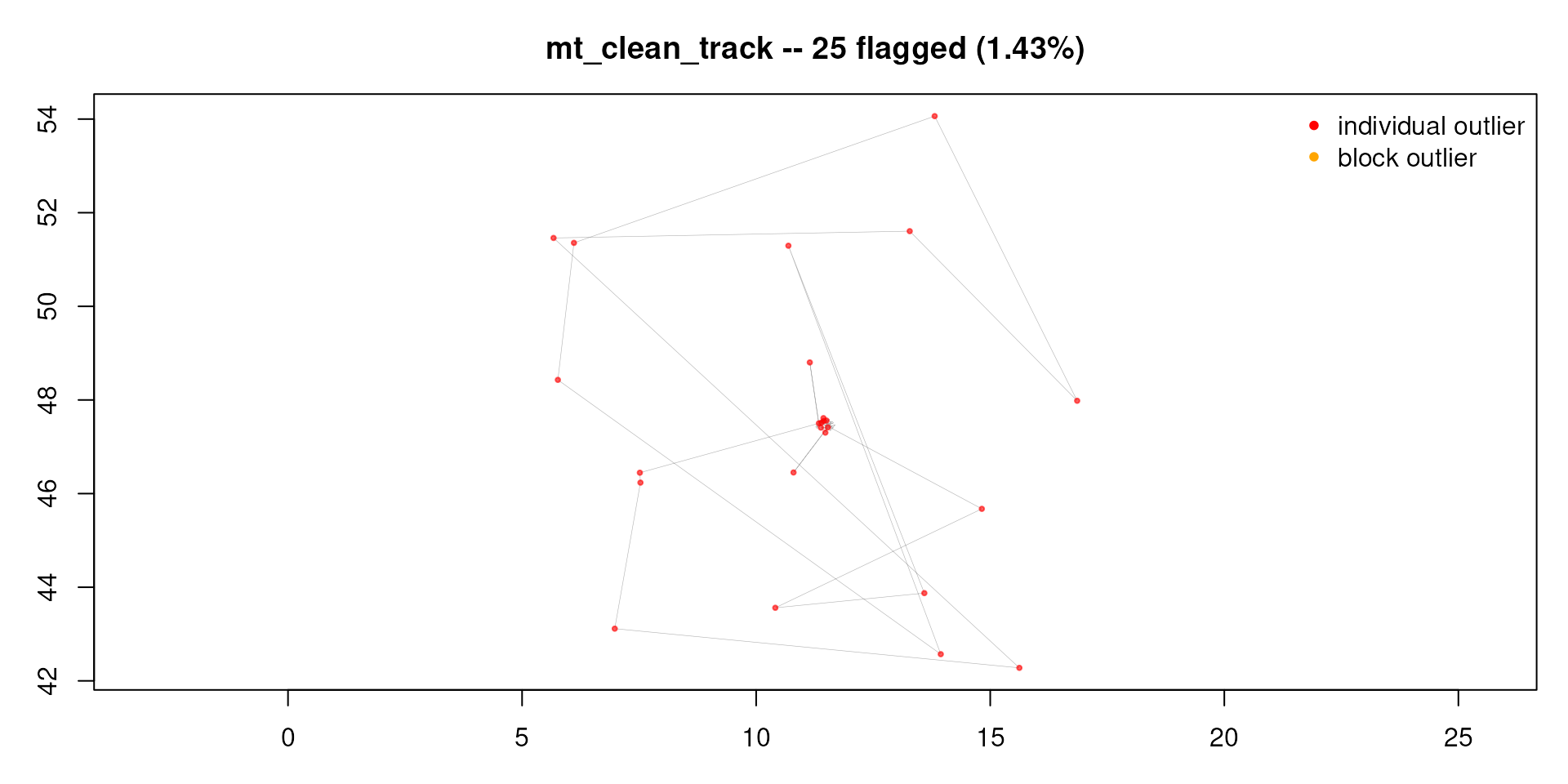
cat("Before:", nrow(cpf_a), " After:", nrow(clean),
" Removed:", nrow(cpf_a) - nrow(clean), "\n")
#> Before: 1748 After: 1723 Removed: 25The diagnostic plot shows the kept track and the removed fixes by
detector colour. If you want to inspect which primitive caught
what, set remove = FALSE to keep all rows with the
per-detector flag columns attached:
flagged <- mt_clean_track(cpf_a, remove = FALSE, plot = FALSE)
#> No physiological speed cap supplied -- running with a data-driven cap chosen from your track. This works well for most cases. If your animal has multiple behavioural states (e.g. perched and flying) or you expect sustained-spoof errors, supplying `v_max =` (a published top speed in m/s) or `(mass = ..., mode = ...)` for the allometric estimate gives sharper results. See `?v_phys_estimate` for the allometric helper; `?mt_clean_track` documents the failure modes of the auto-cap in detail.
#> Auto-cap landed at 60.2 m/s -- above the Hirt 2017 95% upper CI of the maximum biological speed (~52.6 m/s). The gap finder is detecting a structural break within the outlier tail. Supply `(mass, mode)` or a hard `v_max` for a principled physiological cap. See `?v_phys_estimate`.
#> Iter 1: bridge=20 prob=5 speed=23 detour=11 (v_max=60.2) | conjunction=19 | new=19 cumulative=19
#> Iter 2: bridge=4 prob=17 speed=6 detour=5 (v_max=25.5) | conjunction=6 | new=6 cumulative=25
#> Iter 3: bridge=0 prob=12 speed=0 detour=2 (v_max=-) | conjunction=0 | new=0 cumulative=25
#> === mt_clean_track: 25 flagged (1.430% of 1748); stopped: no_new_flags ===
#> Returning all rows with flag columns attached. To drop flagged rows, either re-run with remove = TRUE (the default) or subset: x[!x$is_outlier, ].
table(flagged$is_outlier)
#>
#> FALSE TRUE
#> 1723 25
table(bridge = flagged$flagged_by_bridge,
detour = flagged$flagged_by_detour,
prob = flagged$flagged_by_prob,
speed = flagged$flagged_by_speed)
#> , , prob = FALSE, speed = FALSE
#>
#> detour
#> bridge FALSE TRUE
#> FALSE 1695 2
#> TRUE 0 4
#>
#> , , prob = TRUE, speed = FALSE
#>
#> detour
#> bridge FALSE TRUE
#> FALSE 20 2
#> TRUE 0 0
#>
#> , , prob = FALSE, speed = TRUE
#>
#> detour
#> bridge FALSE TRUE
#> FALSE 4 0
#> TRUE 7 3
#>
#> , , prob = TRUE, speed = TRUE
#>
#> detour
#> bridge FALSE TRUE
#> FALSE 1 0
#> TRUE 9 1The columns flagged_by_bridge,
flagged_by_detour, flagged_by_prob,
flagged_by_speed, flag_iteration, and
block_id track the provenance of each flag. The
error_class column records which class-aware rule
(consensus, geometric_spike, state_anomaly, kinematic_confluence, block,
physiological, state_transition_buffered) caused the flag — see
vignette("OUTLIER_2_diagnose_clean_track", package = "move2utils")
for the taxonomy.
When to supply a physiological speed cap
The default call leaves v_max = NULL, in which case the
speed-cap detector chooses a data-driven threshold by dip-test-validated
entropy valley. That is safe on clean data and on most species, but it
has a known sensitivity floor: long, internally-coherent error clusters
(typical of GPS spoofs or multi-hour position jumps) carry small
internal step speeds and are visible only at their boundaries. A single
fixed physiological cap, peeled to convergence, dissolves them
cleanly.
In addition, the block-expansion step that follows the
per-fix detectors uses v_max as a connectivity threshold to
identify topologically-isolated outlier clusters. Block expansion only
fires when the resulting component partition shows the expected
“trajectory + isolated clusters” signature (a clearly dominant component
plus a clean log-gap to the rest); if the data-driven cap sits inside
the species’ normal flight range, block expansion would sever continuous
trajectory and is automatically declined. The gate prints its decision
in the running narration. To enable block expansion on a fast-flying
species, supply a physiological cap via v_max = ... or the
(mass, mode) allometric route below.
## Eagle physiological cap is around 30 m/s sustained;
## vulture around 25 m/s; stork around 50 m/s.
## Supply v_max when species biology gives you the number.
clean <- mt_clean_track(track, v_max = 30)When v_max is supplied, mt_clean_track()
first runs mt_peel_speed() to convergence at that cap, and
then runs the remaining primitives on what survives. Use
mt_suggest_speed_cap() as a diagnostic helper — it reports
the entropy and gap candidates and warns when they disagree, but it
deliberately does not pick v_max for you.
mt_suggest_speed_cap(track)A principled default from body mass and locomotor mode
If you do not have a published species-specific speed cap, you can
derive a principled v_max from body mass and locomotor mode
using the Hirt et al. (2017) general scaling law. The helper
v_phys_estimate(mass, mode) returns the predicted maximum
sustained burst speed in m/s (with a parameter-uncertainty confidence
interval); mt_clean_track() accepts the same
(mass, mode) pair directly.
## Direct call: returns a printable estimate with CI
v_phys_estimate(mass = 5, mode = "flying") # eagle-class
## Use in the cleaning pipeline:
clean <- mt_clean_track(track, mass = 5, mode = "flying")The diagnostic mt_suggest_speed_cap() accepts the same
arguments and overlays the allometric prediction on the step-speed
distribution alongside any user estimate, so all three perspectives —
empirical break, allometric prediction, user-supplied v_max
— appear on one plot. Disagreement between them is itself diagnostic: an
empirical break far above the allometric prediction is a contamination
signal, while an empirical break far below it is a within-distribution
structure (behavioural state changes, gait transitions) that should not
be cut at.
mt_suggest_speed_cap(track, mass = 5, mode = "flying", v_max = 30)If you are uncertain about the locomotor mode (e.g. a stork that
flies and walks, a seal that swims and walks), pass mass
alone and the diagnostic shows all three mode-specific lines so you can
read the implied cap for each.
## Compare flying / running / swimming predictions for the same mass
mt_suggest_speed_cap(track, mass = 1)Where to find body mass for your species
Body mass is the only species-level input the allometric helper needs. A few practical routes:
-
Movebank reference data. If you downloaded the track from Movebank, per-individual mass is often already in the metadata table:
ref <- move2::mt_track_data(track) ref$animal_mass # in kg, when populated EltonTraits 1.0 (Wilman et al. 2014) for birds and mammals; PanTHERIA (Jones et al. 2009) for mammals; Amniote (Myhrvold et al. 2015) for birds, mammals and reptiles. All published as ESA Data Paper supplements; download the CSV once and look up by Latin name.
traitdataformR package (github.com/EcologicalTraitData/traitdataform) aggregates the above under a single schema and is the closest thing to a programmatic API.Wikidata SPARQL endpoint is the lightest live route — query
wdt:P2067(body mass) for a species’ Wikidata Q-id. No file management, but coverage and curation vary by taxonomic group.
Curate the metadata once, save it alongside the track, and the allometric prediction follows.
Touring the primitives
Each primitive is exported on its own for users who want to inspect a single signal or build their own composition.
Bridge residual — geometric
mt_flag_outliers_bridge() scores each fix by its
deviation from the time-weighted Brownian-bridge mean of its temporal
neighbours, normalised by bridge width. The width depends only on
timestamps, so an outlier cannot inflate its own denominator. The
directional variant decomposes the residual into along-track and
across-track components and classifies the kind of error at each flag.
See
vignette("OUTLIER_4_outlier_bridge", package = "move2utils").
br <- mt_flag_outliers_bridge(cpf_a, plot = FALSE)
#> Input is in longitude/latitude. Auto-projecting to a local AEQD for Euclidean bridge math; output is returned in the original CRS.
#> Running bridge-residual detection (method = combined) on 1748 locations...
#> Iter 1: flagged 6 (break at eta = 1591.91 / eta_perp = 406.83).
#> Iter 2: flagged 7 (break at eta = 1472.59 / eta_perp = 56.83).
#> Iter 3: flagged 7 (break at eta = 1254.78 / eta_perp = 505.75).
#> === 20 outliers (1.14% of 1748) ===
cat("bridge flagged:", sum(br$is_outlier), "\n")
#> bridge flagged: 20Movement-metric probability — kinematic
mt_flag_outliers() scores each fix by the joint
empirical probability of its step length, turning angle, and their
gap-aware auto-differences. It catches fixes whose movement kinematics
conflict with the animal’s usual behaviour even when the geometry alone
looks plausible.
pr <- mt_flag_outliers(cpf_a, plot = FALSE)
#> Calculating movement metrics...
#> ACF-derived alpha: 0.215 (r_speed=0.816, r_angvel=0.057)
#> Calculating probability distributions...
#> Note: step-length range/IQR = 8231 is extreme;
#> teleport-class GPS errors are better handled by
#> mt_filter_gps_quality() (drop fixes with <5 satellites)
#> and mt_flag_outliers_bridge() (geometric, leverage-immune).
#> step_transform = "log" is available but can hide
#> physiologically-plausible joint turn/step outliers.
#> Calculating joint probabilities...
#> Identifying outliers...
#>
#> 3 locations (0.2%) have NA probabilities --will be kept.
#> === 11 outliers (0.63% of 1748) ===
cat("probability flagged:", sum(pr$is_outlier), "\n")
#> probability flagged: 11The default threshold_type = "gap" uses a broken-stick
null model on the log-probability tail; "entropy" is the
conservative alternative (no-op on clean data);
"significance" and "percentile" retain the
older z-score and quantile thresholds.
Step-level speed cap — physical
mt_flag_speed_cap() flags individual steps whose implied
speed exceeds a threshold. By default the threshold is data-driven
(auto, dip-test-validated). Pass
threshold_type = "hard" with v_max for a fixed
cap; pass mt_peel_speed(x, v_max) for the iterative peel
that dissolves coherent clusters.
sc <- mt_flag_speed_cap(cpf_a, plot = FALSE)
#> Auto-cap landed at 60.1 m/s -- above 55.0 m/s (Hirt 2017 universal upper-CI (~52.6 m/s, fastest flier)). The gap finder is detecting a structural break within the outlier tail rather than between bulk and outliers. Supply `(mass, mode)` to `mt_clean_track()` (or pass a hard `v_max`) for a principled physiological cap. See `?v_phys_estimate`.
#> Speed cap: 60.1041 m/s (auto) -- 23 fix(es) flagged. Total is_outlier = 23 (1.316%).
#> === 23 outliers (1.32% of 1748) ===
cat("speed flagged:", sum(sc$is_outlier), "\n")
#> speed flagged: 23Multi-scale persistence annotation and other variants
mt_persistence_score() annotates any flagger’s output
with a per-flag confidence score derived from how anomalous each flagged
fix looks when viewed over wider temporal windows
(scales = c(2, 4, 8) by default). It does not modify
is_outlier – it adds a persistence_count
column ranging 1 (flagged only at native resolution) to 4 (flagged at
every validation scale). Empirical work (see
vignette("OUTLIER_5_persistence_score", package = "move2utils"))
shows the score is class-conditionally informative for cleaning cascade
output: high persistence on state_anomaly and
consensus flags is supporting evidence; on
geometric_spike flags the class is empirically pure on the
synthetic data and the score adds nothing.
clean <- mt_clean_track(cpf_a, plot = FALSE, remove = FALSE)
#> No physiological speed cap supplied -- running with a data-driven cap chosen from your track. This works well for most cases. If your animal has multiple behavioural states (e.g. perched and flying) or you expect sustained-spoof errors, supplying `v_max =` (a published top speed in m/s) or `(mass = ..., mode = ...)` for the allometric estimate gives sharper results. See `?v_phys_estimate` for the allometric helper; `?mt_clean_track` documents the failure modes of the auto-cap in detail.
#> Auto-cap landed at 60.2 m/s -- above the Hirt 2017 95% upper CI of the maximum biological speed (~52.6 m/s). The gap finder is detecting a structural break within the outlier tail. Supply `(mass, mode)` or a hard `v_max` for a principled physiological cap. See `?v_phys_estimate`.
#> Iter 1: bridge=20 prob=5 speed=23 detour=11 (v_max=60.2) | conjunction=19 | new=19 cumulative=19
#> Iter 2: bridge=4 prob=17 speed=6 detour=5 (v_max=25.5) | conjunction=6 | new=6 cumulative=25
#> Iter 3: bridge=0 prob=12 speed=0 detour=2 (v_max=-) | conjunction=0 | new=0 cumulative=25
#> === mt_clean_track: 25 flagged (1.430% of 1748); stopped: no_new_flags ===
#> Returning all rows with flag columns attached. To drop flagged rows, either re-run with remove = TRUE (the default) or subset: x[!x$is_outlier, ].
annotated <- mt_persistence_score(clean, silent = TRUE)
flagged <- which(annotated$is_outlier)
print(table(annotated$persistence_count[flagged]))
#>
#> 3 4
#> 1 24mt_sequential_outliers() and
mt_combined_outliers() provide sequential-scan and
majority-vote variants of the probability detector; see their reference
pages for details.
Suggested workflow
- Load your
move2object; drop empty geometries and duplicates. - Run
mt_filter_gps_quality()if your tag exposes satellite/DOP/horizontal-accuracy columns. - Run
mt_clean_track()with default settings. - If you have a species physiological speed cap, call
mt_clean_track(x, v_max = ...)or, equivalently, supply(mass, mode)for an allometric prior. - Inspect the diagnostic plot; refine with the per-primitive functions only if the unified call misses something specific.
-
Run
mt_diagnose_clean_track()on the result to check whether the run was healthy. The diagnostic surfaces the patterns the single-figure plot of the cleaned track does not — bimodal behaviour, sustained migration bands, non-converging iteration — and tells you when to escalate to state-conditional analysis.
Health-check after cleaning —
mt_diagnose_clean_track()
res <- mt_clean_track(track, mass = 3.4, mode = "flying",
plot = FALSE, remove = FALSE)
diag <- mt_diagnose_clean_track(res)Six panels (single-track) or six-with-cohort-overview (multi-track)
that let you eyeball whether the run was healthy. Each panel that trips
a concern prints a one-line interpretive note pointing at the
appropriate remedy. See
vignette("OUTLIER_2_diagnose_clean_track", package = "move2utils")
for a full walkthrough on real data.
Further reading
If this is your first time, read in this order: this vignette, then
diagnose_clean_track to interpret your run, then
state_conditional if your animal has multiple behavioural
states. The remaining vignettes go deeper as needed.
-
vignette("OUTLIER_2_diagnose_clean_track", package = "move2utils")— the post-run health check -
vignette("OUTLIER_3_state_conditional", package = "move2utils")— when the diagnostic flags bimodal behaviour, the recipe for cleaning each behavioural state separately. -
vignette("OUTLIER_4_outlier_bridge", package = "move2utils")— the bridge primitive and the directional error-morphology classifier; for users who want fine-grained control over just one detector. -
vignette("OUTLIER_5_persistence_score", package = "move2utils")— multi-scale annotation that scores how confidently each flag is an outlier; useful as a post-cleaning confidence filter. -
vignette("OUTLIER_heterogeneous_error_regimes", package = "move2utils")— outlier detection with heterogeneous error regimes: one sensor at a time -
vignette("OUTLIER_example_outlier_whitestork", package = "move2utils")— a full narrated cleaning pipeline on a real high-frequency stork track. -
vignette("OUTLIER_example_leo_migration", package = "move2utils")— outlier detection on irregular, large-scale satellite data.
Appendix: downloading your data from Movebank
If you’re pulling your track from Movebank, a little care at the download step pays off later: the cleaning pipeline can use Movebank’s per-fix quality information (how many satellites the fix used, how confident the tag was, what kind of fix it was) to make sharper decisions about which fixes to drop. The good news is you don’t need to do anything fancy — you just need to ask for those columns explicitly when you download.
Principle: if Movebank has the per-fix quality information,
ask for it. The pipeline uses every quality column it can find
— satellite count, DOP (a precision-of-fix indicator), fix type,
device-reported horizontal accuracy, Argos location class. Each one
independently sharpens the decision on borderline fixes. If a column is
missing, the pipeline still runs — mt_filter_gps_quality()
skips any criterion whose column it can’t find, and the bridge detector
falls back to a user-supplied location_error — but
quality-informed flags are always more reliable than geometry-only
flags. The cost of the extra columns is small in bytes and zero in
latency since the API streams them in the same request.
Two things to ask for at download time:
-
Restrict to GPS only via
sensor_type_id = "gps". Many tags (e-obs in particular) emit accelerometer bursts as separate records with empty geometries; without this restriction a download of a small bird can be ~5× larger than the GPS data and 80% empty rows. -
List the quality columns explicitly in
attributes = c(...). Whilemovebank_download_study()returns a sensible default attribute set, naming the quality columns by hand makes the data dependency auditable and protects against studies whose default attributes have been customised away from Movebank’s canonical schema.
The columns move2utils recognises out of the box:
| Movebank canonical column | What it represents | Used by |
|---|---|---|
gps_satellite_count /
gnss_satellite_count
|
number of satellites used in the fix |
mt_filter_gps_quality(),
mt_flag_outliers(quality_columns = ...)
|
gps_hdop / gnss_hdop
|
horizontal dilution of precision | filter + probability weight |
gps_pdop / gnss_pdop
|
3D positional dilution of precision | filter + probability weight |
gps_dop / gnss_dop
|
unspecified DOP (for tags that emit a single number) | filter + probability weight |
gps_fix_type / gnss_fix_type
|
2D vs 3D fix | filter (drops 2D) + weight |
eobs_horizontal_accuracy_estimate |
per-fix 1-σ horizontal accuracy in metres (e-obs tags) | filter + weight + bridge anchor sigma |
argos_lc |
Argos location class (G, 3, 2, 1, 0, A, B, Z) | filter + weight + bridge sigma via the CLS table |
The recommended download pattern:
## download all attributes available in the study
track <- move2::movebank_download_study(
study_id,
sensor_type_id = "gps",
attributes= "all")
## or select specific attibutes to download
track <- move2::movebank_download_study(
study_id,
sensor_type_id = "gps",
attributes = c(
## minimum core (always retrieved, listed for clarity)
"timestamp", "location_lat", "location_long",
"individual_local_identifier",
## quality columns consumed by mt_filter_gps_quality() and
## mt_flag_outliers's quality_columns weighting
"gps_satellite_count",
"gps_hdop",
"gps_pdop",
"gps_dop",
"gps_fix_type",
## per-fix horizontal accuracy in metres (e-obs tags); also
## consumed by the bridge detector as its anchor sigma
"eobs_horizontal_accuracy_estimate",
## Argos location class (when relevant)
"argos_lc"
)
)
## For modern multi-constellation tags that emit GNSS_* names, swap
## the gps_* prefix above for gnss_*. Where both prefixes are
## present in a study, GNSS is preferred.
## If you just want a quick look without quality information, pass
## `attributes = NULL` for the absolute minimum (timestamp,
## location, track id). The pipeline will then run in degraded
## mode -- mt_filter_gps_quality() becomes a no-op and the bridge
## falls back to your `location_error` argument.Heads-up on the first download from a study. Movebank requires you to accept each study’s licence before it returns data. On a first call to a study you haven’t downloaded before, the request above will fail and the error message will include the full licence terms, ending with a line like:
'license-md5'='306ac0a2292eb02b9b42d1b5faeca786'(the exact hash depends on the study). Copy that string back into your call as a named argument:
track <- movebank_download_study(
study_id, sensor_type_id = "gps", attributes = c(...),
"license-md5" = "306ac0a2292eb02b9b42d1b5faeca786"
)The quoting around "license-md5" is there because the
name contains a hyphen. You only need to do this once per study; future
calls remember the acceptance for that login.
If you can’t restrict the attributes at download time and the object
arrives with empty rows, drop them before passing to the cleaning
pipeline: x <- x[!sf::st_is_empty(x), ].
Non-Movebank vendor data
If your data comes from a vendor whose column names differ from the
Movebank canonical schema (Vectronic, Lotek, Telonics, Sirtrack, custom
feeds), the auto-detection above won’t find your quality columns and the
cleaning pipeline runs in degraded mode (it’ll still work, just without
the extra information). A unified quality-column resolver — slot-based,
with a user-supplied alias map — is in design (see
DESIGN_quality_columns.md at the package root); for the
current release the workaround is to either rename the vendor columns to
the Movebank canonical names before running
mt_clean_track(), or pass per-fix quality functions
directly via
mt_flag_outliers(quality_columns = list(...)).